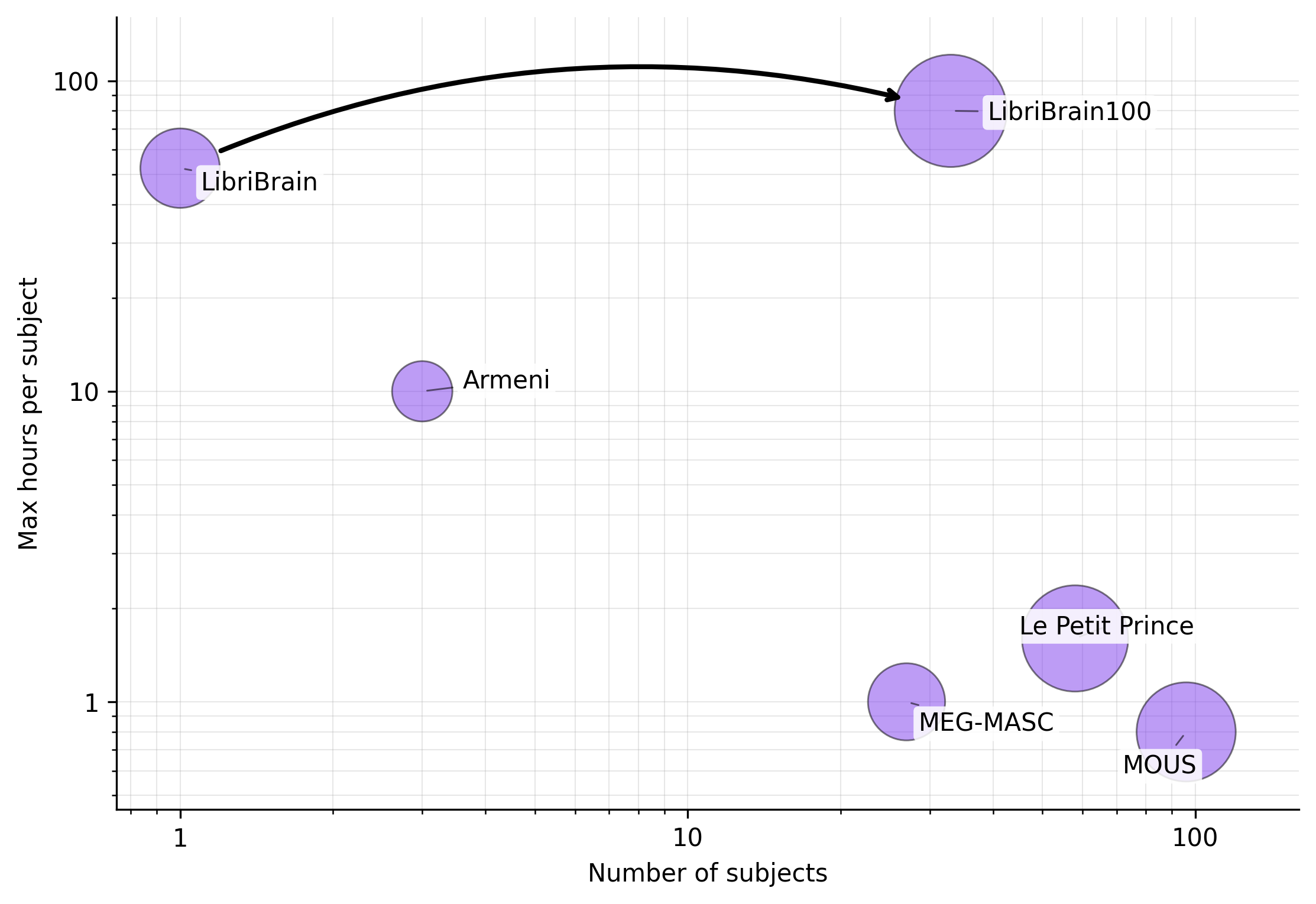
The 2026 PNPL Competition builds on the success of our inaugural year with a more ambitious task and a significantly expanded dataset. This year, participants will tackle Word Classification — predicting which word a subject is hearing from MEG brain recordings.
What's New
New Task
Word Classification — decode which of 50 words a subject is hearing from MEG data
New Dataset
Introducing the new LibriBrain100 dataset, now with over 100 hours of MEG data
Two Tracks
Go Deep on a single subject or Broad across 32 — enter either or both
Three Months
Submissions run 15 July – 15 October 2026 (Anywhere on Earth).
The Dataset: LibriBrain100
LibriBrain100 is a major expansion of the original LibriBrain dataset, bringing the total to over 100 hours of MEG data. It pairs the deeply-sampled subj0 recordings behind the Deep track — spanning audiobooks, phonetically balanced speech corpora (TIMIT, MOCHA-TIMIT), and narrative podcasts — with varying amounts (~10–40 minutes each) from 32 additional subjects behind the Broad track.
This multi-subject dataset opens the door to cross-subject generalisation — a critical challenge for practical brain-computer interfaces. How much data does it take to reach useful performance on a new subject?